法政大学国際文化学部
情報システム概論
担当 重定 如彦
2009年12月1日
第10回 ソフトウェア(その2)
1. 基本ソフトウェアその2 〜言語処理ソフトウェア〜
初期のコンピュータではプログラムは配線ケーブルをつなぎかえることでコンピュータのハードウェア回路を人間が手で変更するという方法で行っていましたが、プログラム内蔵方式のコンピュータの出現によってソフトウェアによって作成するようになりました。
初期のプログラミングでは機械語と呼ばれる2進数の数字の羅列を人間が直接記述していましたが、機械語は人間にとっては非常に扱いにくい言語であるため、複雑で巨大なプログラムを作成するためには大変な労力が必要でした。そこで、機械語の命令を人間がわかりやすいアルファベットの記号に置き換えたアセンブラ言語が登場しました。アセンブラ言語は、機械語で直接プログラムを記述するよりもはるかに効率の良い言語でしたが、それでも複雑なプログラムを作成しようとすると大変な労力が必要です。例えば、以前の授業でアセンブラ言語で掛け算を行うプログラム例を挙げましたが、たかが掛け算を記述するだけで十数行ものプログラムが必要となってしまいます。そこで、アセンブラ言語よりもさらに人間の言葉に近い表現力を持つ高級言語と呼ばれる言語が開発されました。
例えばC言語という高級言語で、7*5を計算し、メモリに格納するには、
int A;
A
= 7 * 5;
というたった2行のプログラムを記述するだけで良いのです。
注:一行目は整数(integer)を格納する領域をメモリに確保してそのメモリにAという名前をつけろという意味です。アセンブラ言語で言うと
A DS 1 に相当します。
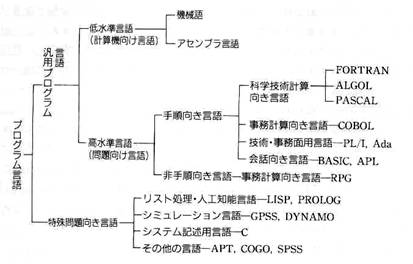
高級言語は、作成するプログラムの用途に応じて下図のようにこれまで様々な言語が開発されてきました。以下に代表的な高級言語を紹介します。
·
COBOL(コボル)
事務計算用の高級言語としてアメリカ国防省を中心に開発された言語で、英語に近い表現になっています。現在でも広く使用されている高級言語の一つです。
·
FORTRAN(フォートラン)
科学技術用言語としてIBM社によって開発された言語で、複雑な数式をそのまま表現することができるのが特徴です。
·
BASIC(ベーシック)
アメリカのダートマス大学で開発された高級言語で、初心者向きの会話型の言語です。かつては技術計算、事務計算、ゲームなどパソコンで広く使用されていました。
·
Visual
BASIC
BASIC言語を基本にして、Windows用のソフトウェアを開発するために作られた言語です。ビジュアルなエディタを使ってアプリケーションを開発できるのが特徴です。
·
C(シー)、C++(シープラスプラス、又はシープラプラ)
アメリカのベル研究所で開発された高級言語で、OSなどのシステムを記述する為の言語として広く利用されています。1983年にC言語のオブジェクト指向という概念を取り入れたC++という言語が開発されています。
·
Visual
C++
C++言語を基本にして、Windowsのアプリケーションをビジュアルなエディタを使って効率よく作成できるように開発された言語です。Visual
C#という言語もあります。
·
LISP(リスプ)
アメリカのMITで開発されたリスト処理用言語で、人工知能の研究で使用されています。
·
Java(ジャバ)
アメリカのサン・マイクロシステム社が開発した言語で、C++言語に似たオブジェクト指向型のプログラミング言語です。あらゆるプラットフォーム上で動くことを目的の一つとして開発された言語です。(他の言語では基本的にOSが異なるとプログラムは動きません)
2. コンパイラとインタープリタ
アセンブラ言語の場合、アセンブラ言語で記述されたプログラムを機械語命令に翻訳すためのアセンブルという作業を行いました。高級言語はコンパイラ(compiler)言語とインタープリタ(interpreter)言語の2種類があり、記述したプログラムを実行する方法が異なります。
·
コンパイラ言語
コンパイラ言語はアセンブラ言語と同様に、記述したプログラムを機械語のプログラムに一旦翻訳し、翻訳されたプログラムを実行します。この翻訳作業のことをコンパイルと呼び、コンパイルを行うプログラムのことをコンパイラと呼びます。アセンブラ言語の命令と機械語の命令に1対1に対応していましたが、高級言語の場合はそうではなく、高級言語で記述された命令をその命令に相当する機械語の羅列に変換します。例えば機械語の命令に掛け算を行う命令はありませんので、例えばC言語で7*5を計算するプログラムを1Pのプログラムのように記述した場合、実際には前々回の授業で7*5を計算する機械語のプログラムに翻訳されます。CPUの種類によって用意されている機械語の命令の種類は異なっていますので、コンパイラは、CPUの種類毎に別のものを用意する必要があります。実際にはOSがある程度のCPUの違いを吸収してくれるので、OSの種類毎に別のコンパイラを用意する必要があるといったほうが現状にあっていると言えるでしょう。
·
インタープリタ言語
インタープリタ言語は、記述したプログラムを直接解釈して実行するインタープリタと呼ばれるプログラムを使ってプログラムを実行します。コンパイラ言語と異なり、記述したプログラムを「機械語のプログラムに翻訳する(=コンパイル)」という作業を行う必要がないので、プログラムを試作したり、プログラムの一部を変更した場合でもすぐに実行できるという利点があります。インタープリタ言語は、実行するたびに毎回インタープリタがプログラムを解釈しながら実行するために、実行速度がコンパイラ言語で作成されたプログラムより処理速度が遅くなるという欠点があります。例えていうならば、元々英語で書かれた文章を読むときに、それを一旦日本語に翻訳し翻訳された本を読むのがコンパイラ、毎回通訳を用意して読みたい部分を通訳してもらいながら読むのがインタープリタです。高級言語の中では、BASIC、LISP、Javaなどがインタープリタ言語です。
3. 基本ソフトウェアその3 〜サービスソフトウェア〜
サービスソフトウェアは、プログラムの作成や実行のサポートを行うソフトウェアです。
·
リンケージエディタ
プログラムでは、小さな部品(プログラム)を組み合わせて全体として大きな動作を行うプログラムを作るという手法がよくとられます。リンケージエディタはアセンブラやコンパイラで作成された複数の機械語のプログラムを組み合わせて(=小さな部品のプログラムの集まり)一つの大きなプログラムに結合させるという動作を行うソフトウェアです。
·
デバッガ
プログラムにはエラーはつきものです。どんなに熟練したプログラマでも大きなプログラムをエラーなしにいきなり完成させることは不可能といっても過言ではありません。デバッガはプログラムのエラーの検査(この検査のことをデバッグ(debug)と呼びます)を行う為のプログラムで、プログラムを順番に実行させてレジスタやメモリの中身を調べたり、プログラムの特定の場所で実行を止めるといった機能を持っています。アセンブラの実行の際に使用したCOMETもデバッガの機能を持っています。
·
ローダ
コンパイラやリンケージエディタが作成した機械語のプログラムを実行する為にメモリに読み込ませるためのプログラムです。
4. ファイルシステム
ファイルシステムはOSのデータ管理プログラムの役割の一つであり、ハードディスクやフロッピーディスクなどの補助記憶装置に格納されたデータやプログラムを「ファイル」という形で扱う為のシステムです。ファイルシステムは主に以下のような役割を持ちます。
·
名前(ファイル名)によるファイルの検索
ファイルシステムに格納されたファイルにはそれぞれ名前をつけることができ、その名前を使ってファイルを参照することができます。ファイルとファイルシステムの関係を日用品で例えると、本と本棚の関係に似ており本棚が補助記憶装置、本がファイルに相当します。通常、本には必ずタイトルがついており、本の背表紙には本のタイトルが印刷されています。本棚には背表紙を手前に向けて本を格納するので、本棚に非常にたくさんの本が格納されていても、本の背表紙をみて自分の見たい本を探すことができます。
この本のタイトルに相当する部分がファイルの「ファイル名」であり、ファイル名を使って特定のファイルを検索する機能はファイルシステムの重要な機能の一つです。
·
階層構造による整理
本棚に本を格納する場合、一般的に棚をジャンルで分類して整理を行います。このような整理を行うことで、自分の探したい本のジャンルを知っていれば、本棚のどこを探せば目的の本が見つける事ができるかを容易に推測することができるようになります。ファイルシステムの場合、フォルダ(システムによってはディレクトリ(directory)とも呼ばれます)がこの棚に相当します。例えばWindowsの場合、WINDOWSという名前のフォルダにWindowsのOSに関係するファイルを整理します。ファイルシステムの場合、さらにフォルダの中にフォルダを作ることができ、これによってファイルの種類をさらに細かく分類して整理することができます。このようなファイルシステムの構造を階層構造と呼びます。
·
アクセス制御
個人用のコンピュータの場合はあまり問題になりませんが、大学や企業では一つの非常に高性能なコンピュータを複数の人間が使うことがあります。このような場合、プライバシーや機密保持の問題などから、ファイルを操作(アクセス)することができる人間を制限することがあります。このようなファイル操作を制御する機能のことをアクセス制御と呼びます。本棚で例えると、機密書類や日記など他人に見られたくない本を入れる棚に蓋をして鍵をかけることで、鍵を持っている人間しか本を読めないようにするということです。また、ファイルシステムの場合、棚(=フォルダ)だけではなく、一つ一つの本(=ファイル)そのものに鍵をかけて特定の人間しか読むことができないようにすることも可能です。アクセス制御は何の操作を許可するかによって、「読み込み許可」、「書き込み許可」、「実行許可」の3種類があります。これらのそれぞれに対して誰に対して(「作成者」と「それ以外の人」etc)それらの行動を許可するかを細かく設定できるシステムも存在します。
機密で無い一般的なファイルのアクセス制御には、ファイルの製作者に対しては読み込み、書き込み、実行をすべて許可し、それ以外の人に対しては読み込みと実行のみを許可(要するに書き込みを禁止)するという設定を行うのが一般的です。
5. ファイルの構成要素
ファイルシステムのもう一つの重要な役割として、限られたサイズの補助記憶装置の中でファイルを正しく管理するというものがあります。ここでいう管理には、ファイルのデータの格納、データの更新、データの参照などが挙げられます。最初にファイルの中身がどのように補助記憶装置(以下ディスク)の中に格納されているかについて説明します。
メモリの場合は、データが格納されているアドレスを指定することで、指定したアドレスの内容を1バイトずつ読み出すことが可能でしたが、ディスクはメモリ(=数ギガバイト)と比較してサイズが大きいものでは数万倍(数テラバイト)になるものがあるため、ディスクのアドレスを指定するためには大きなサイズのデータが必要になります。また、ディスクはメモリと異なりアクセス速度が低速なので、一バイトずつデータを読み込むと非常に時間がかかってしまいます。また、逆にファイルのデータを全部一気に読み込む方法では、ファイルのサイズが非常に大きかった場合や、ファイルの中で一部分のデータしか必要でない場合は効率が悪くなってしまいます。そこでファイルシステムではファイルの中身をレコードと呼ばれる数十〜数千バイトのデータを一まとまりのデータで分割し、ファイルの読み書きなどの操作を行う際にはレコード単位で行います。これによって以下のような利点を得ることができます。
·
ディスクのデータの場所を示すアドレスに必要なデータ量を減らすことができる。
·
補助記憶装置では、レコード(数十〜数千バイト)単位でデータを一気に読み書きするほうが、一バイトずつデータを読み書きするよりも高速に実行できる。
レコードは他のレコードと区別を行う為のキー(キーの使い方については後述します)と呼ばれるデータとファイルの中身であるデータ項目から構成されます。
レコードをさらにいくつか一まとまりにしたものをブロックと呼び、一つのブロックに格納されるレコードの数をブロック化係数と呼びます。ブロックはディスクをレコードよりもさらに大きな単位で区分する為に使用されます。ブロックはファイルシステムの種類によって使用される場合とされない場合がありブロックを使用するものをブロック化レコード、使用しないものを非ブロック化レコードと呼びます。
注:ブロックは「物理レコード」とも呼ばれます。その場合、ブロックを構成するレコードの事を「論理レコード」と呼ぶことで名前を区別します。このプリントの説明では、まぎらわしいので、こちらの表記は使用しません。
6. レコード形式
レコードには以下の3つの形式があります。
·
固定長レコード
レコードの長さがすべて同じ(ファイルシステムで定められる)形式のレコードです。
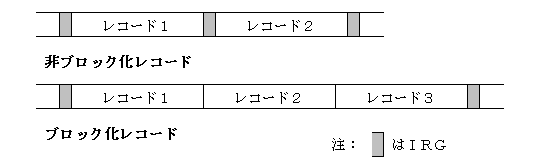
非ブロック化レコードとブロック化レコードのそれぞれの場合があり、以下の図のような形で格納されます。
非ブロック化レコードの場合は、レコードとレコードの間にIRG(Inter
Record Gap)と呼ばれる隙間のデータを入れることで、レコードとレコードの境目を指定します。
ブロック化レコードの場合は、いくつかのレコードをひとまとめにした、ブロックとブロックの間にIRGを入れます。レコードの長さが固定されているので、IRGから長さを数えていけばブロックの中のどこでレコードが切れるかを知ることができます。
固定長レコードは、仕組みが単純であり最もよく使用される形式ですが、レコードのサイズが固定であるために、以下例のように無駄が生じる場合があります。
例:非ブロック化レコードで、レコードのサイズが1000バイトの時に、2200バイトのサイズのファイルを例えば前から順に隙間なく格納した場合、以下のようにこのファイルは3つのレコードが使われます。
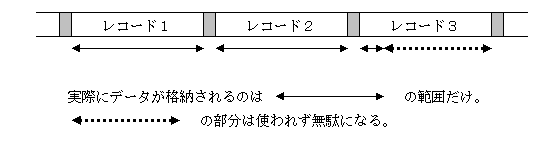
ファイルのサイズが2200バイトで、一つのレコードに1000バイトのデータを格納できるので、レコード1とレコード2にはすべてデータが格納されますが、最後のレコード3の1000バイトのうち実際にデータが格納されるのは最初の200バイトのみとなり、残りの部分は全く使われません。
·
可変長レコード
可変長レコードは、レコードの長さが決まっていない(レコードによって長さが異なる)形式のもので、こちらも非ブロック化レコードとブロック化レコードがあります。
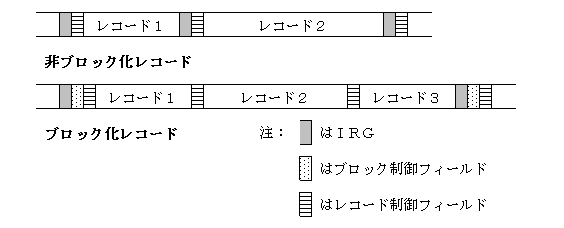
非ブロック化レコードの場合、レコードの長さは実際のレコードのデータを格納する前に、レコード制御フィールドと呼ばれる部分に格納されます。一方ブロック化レコードの場合はブロックの最初に、ブロック制御フィールドと呼ばれる部分を用意し、そこにブロックに関するデータ(ブロック内にレコードがいくつあるかなど)を格納します(注:教科書91ページの図のように、非ブロック化レコードの場合にもブロック制御フィールドが格納される場合もあります)。
可変長レコードは、レコードのサイズを自由に変更することができるので、固定長レコードのような無駄が生じませんが、そのかわりレコードやブロックの長さを格納する制御フィールドが必要になります。その為、一つ一つのレコードのサイズが小さい場合は却って固定長レコードよりも効率が悪くなる場合もあります。
·
不定長フィールド
レコード長が不定でなおかつ制御フィールドを持たない形式です。レコードとレコードの間は固定長レコードのようにIRGを使って指定します。制御フィールドを持たないので、不定長フィールドは非ブロック化レコードしかありません。この形式では、レコードがどこで終わるかを知るには、IRGを探す必要があります。
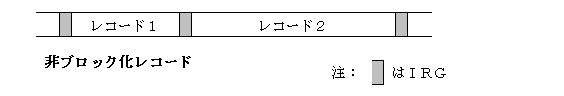
不定長レコードはテキストファイルや実行形式ファイルのような特定の形式を持たないデータを格納する場合に良く使われます。
7. 課題
1.
コンパイラとインタープリタの違いについて、自分の言葉(プリントや教科書の丸写しではだめです)で説明せよ。
2.
Windowsのファイルシステムのアクセス制御について調べ、その特徴を説明せよ。
いずれの場合も、インターネットや書籍で調べた場合は、調べたウェブページのアドレスとタイトルまたは書籍の名前を課題に記述すること。
課題はメールでTAさんに送ってください。
課題のメールは masaki.yamashita.67@gs-art.hosei.ac.jp までお願いします。
質問のメールなどは、sigesada@.hosei.ac.jpまでお願いします。
授業の資料の最新版はhttp://www.edu.i.hosei.ac.jp/~sigesada/にあります。