法政大学国際文化学部
情報システム概論
担当 重定 如彦
2004年11月15日
第9回 ソフトウェア(その2)
1. ファイルシステム
ファイルシステムはOSのデータ管理プログラムの役割の一つであり、ハードディスクやフロッピーディスクなどの補助記憶装置に格納されたデータやプログラムを「ファイル」という形で扱う為のシステムです。ファイルシステムは主に以下のような役割を持ちます。
·
名前(ファイル名)によるファイルの検索
ファイルシステムに格納されたファイルにはそれぞれ名前をつけることができ、その名前を使ってファイルを参照することができます。ファイルとファイルシステムの関係を日用品で例えると、本と本棚の関係に似ており本棚が補助記憶装置、本がファイルに相当します。通常、本には必ずタイトルがついており、本の背表紙には本のタイトルが印刷されています。本棚には背表紙を手前に向けて本を格納するので、本棚に非常にたくさんの本が格納されていても、本の背表紙をみて自分の見たい本を探すことができます。
この本のタイトルに相当する部分がファイルの「ファイル名」であり、ファイル名を使って特定のファイルを検索する機能はファイルシステムの重要な機能の一つです。
·
階層構造による整理
本棚に本を格納する場合、一般的に棚をジャンルで分類して整理を行います。このような整理を行うことで、自分の探したい本のジャンルを知っていれば、本棚のどこを探せば目的の本が見つける事ができるかを容易に推測することができるようになります。ファイルシステムの場合、フォルダ(システムによってはディレクトリ(directory)とも呼ばれます)がこの棚に相当します。例えばWindowsの場合、WINDOWSという名前のフォルダにWindowsのOSに関係するファイルを整理します。ファイルシステムの場合、さらにフォルダの中にフォルダを作ることができ、これによってファイルの種類をさらに細かく分類して整理することができます。このようなファイルシステムの構造を階層構造と呼びます。
·
アクセス制御
個人用のコンピュータの場合はあまり問題になりませんが、大学や企業では一つの非常に高性能なコンピュータを複数の人間が使うことがあります。このような場合、プライバシーや機密保持の問題などから、ファイルを操作(アクセス)することができる人間を制限することがあります。このようなファイル操作を制御する機能のことをアクセス制御と呼びます。本棚で例えると、機密書類や日記など他人に見られたくない本を入れる棚に蓋をして鍵をかけることで、鍵を持っている人間しか本を読めないようにするということです。また、ファイルシステムの場合、棚(=フォルダ)だけではなく、一つ一つの本(=ファイル)そのものに鍵をかけて特定の人間しか読むことができないようにすることも可能です。アクセス制御は何の操作を許可するかによって、「読み込み許可」、「書き込み許可」、「実行許可」の3種類があります。これらのそれぞれに対して誰に対して(「作成者」と「それ以外の人」etc)それらの行動を許可するかを細かく設定できるシステムも存在します。
機密で無い一般的なファイルのアクセス制御には、ファイルの製作者に対しては読み込み、書き込み、実行をすべて許可し、それ以外の人に対しては読み込みと実行のみを許可(要するに書き込みを禁止)するという設定を行うのが一般的です。
2. ファイルの構成要素
ファイルシステムのもう一つの重要な役割として、限られたサイズの補助記憶装置の中でファイルを正しく管理するというものがあります。ここでいう管理には、ファイルのデータの格納、データの更新、データの参照などが挙げられます。最初にファイルの中身がどのように補助記憶装置(以下ディスク)の中に格納されているかについて説明します。
メモリの場合は、データが格納されているアドレスを指定することで、指定したアドレスの内容を1バイトずつ読み出すことが可能でしたが、ディスクはメモリ(=数百メガバイト)と比較してサイズが大きいものでは数万倍(数百ギガバイト)になるものがあるため、ディスクのアドレスを指定するためには大きなサイズのデータが必要になります。また、ディスクはメモリと異なりアクセス速度が低速なので、一バイトずつデータを読み込むと非常に時間がかかってしまいます。また、逆にファイルのデータを全部一気に読み込む方法では、ファイルのサイズが非常に大きかった場合や、ファイルの中で一部分のデータしか必要でない場合は効率が悪くなってしまいます。そこでファイルシステムではファイルの中身をレコードと呼ばれる数十〜数千バイトのデータを一まとまりのデータで分割し、ファイルの読み書きなどの操作を行う際にはレコード単位で行います。これによって以下のような利点を得ることができます。
·
ディスクのデータの場所を示すアドレスに必要なデータ量を減らすことができる。
·
補助記憶装置では、レコード(数十〜数千バイト)単位でデータを一気に読み書きするほうが、一バイトずつデータを読み書きするよりも高速に実行できる。
レコードは他のレコードと区別を行う為のキー(キーの使い方については後述します)と呼ばれるデータとファイルの中身であるデータ項目から構成されます。
レコードをさらにいくつか一まとまりにしたものをブロックと呼び、一つのブロックに格納されるレコードの数をブロック化係数と呼びます。ブロックはディスクをレコードよりもさらに大きな単位で区分する為に使用されます。ブロックはファイルシステムの種類によって使用される場合とされない場合がありブロックを使用するものをブロック化レコード、使用しないものを非ブロック化レコードと呼びます。
注:ブロックは「物理レコード」とも呼ばれます。その場合、ブロックを構成するレコードの事を「論理レコード」と呼ぶことで名前を区別します。このプリントの説明では、まぎらわしいので、こちらの表記は使用しません。
3. レコード形式
レコードには以下の3つの形式があります。
·
固定長レコード
レコードの長さがすべて同じ(ファイルシステムで定められる)形式のレコードです。
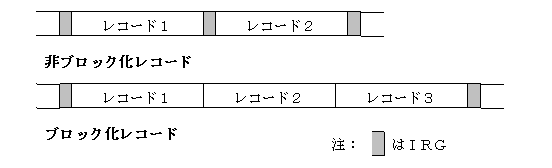
非ブロック化レコードとブロック化レコードのそれぞれの場合があり、以下の図のような形で格納されます。
非ブロック化レコードの場合は、レコードとレコードの間にIRG(Inter
Record Gap)と呼ばれる隙間のデータを入れることで、レコードとレコードの境目を指定します。
ブロック化レコードの場合は、いくつかのレコードをひとまとめにした、ブロックとブロックの間にIRGを入れます。レコードの長さが固定されているので、IRGから長さを数えていけばブロックの中のどこでレコードが切れるかを知ることができます。
固定長レコードは、仕組みが単純であり最もよく使用される形式ですが、レコードのサイズが固定であるために、以下例のように無駄が生じる場合があります。
例:非ブロック化レコードで、レコードのサイズが1000バイトの時に、2200バイトのサイズのファイルを例えば前から順に隙間なく格納した場合、以下のようにこのファイルは3つのレコードが使われます。
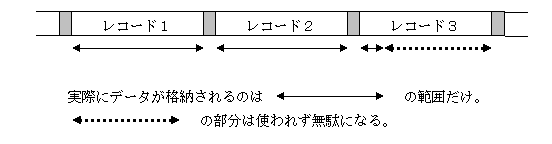
ファイルのサイズが2200バイトで、一つのレコードに1000バイトのデータを格納できるので、レコード1とレコード2にはすべてデータが格納されますが、最後のレコード3の1000バイトのうち実際にデータが格納されるのは最初の200バイトのみとなり、残りの部分は全く使われません。
·
可変長レコード
可変長レコードは、レコードの長さが決まっていない(レコードによって長さが異なる)形式のもので、こちらも非ブロック化レコードとブロック化レコードがあります。
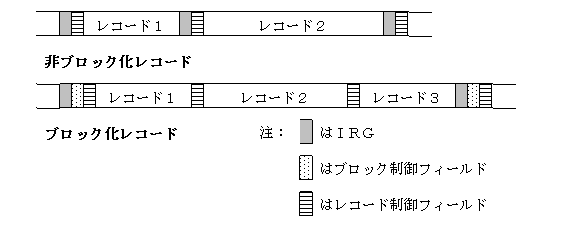
非ブロック化レコードの場合、レコードの長さは実際のレコードのデータを格納する前に、レコード制御フィールドと呼ばれる部分に格納されます。一方ブロック化レコードの場合はブロックの最初に、ブロック制御フィールドと呼ばれる部分を用意し、そこにブロックに関するデータ(ブロック内にレコードがいくつあるかなど)を格納します(注:教科書91ページの図のように、非ブロック化レコードの場合にもブロック制御フィールドが格納される場合もあります)。
可変長レコードは、レコードのサイズを自由に変更することができるので、固定長レコードのような無駄が生じませんが、そのかわりレコードやブロックの長さを格納する制御フィールドが必要になります。その為、一つ一つのレコードのサイズが小さい場合は却って固定長レコードよりも効率が悪くなる場合もあります。
·
不定長フィールド
レコード長が不定でなおかつ制御フィールドを持たない形式です。レコードとレコードの間は固定長レコードのようにIRGを使って指定します。制御フィールドを持たないので、不定長フィールドは非ブロック化レコードしかありません。この形式では、レコードがどこで終わるかを知るには、IRGを探す必要があります。
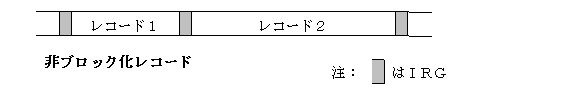
不定長レコードはテキストファイルや実行形式ファイルのような特定の形式を持たないデータを格納する場合に良く使われます。
4. ファイルの処理方式
ファイルのレコードを処理する方式には順処理と直接処理の2種類の方式があります。
·
順処理
どのレコードをアクセスする場合でもレコードをファイルの先頭から順番にアクセスする方式を順処理と呼びます。例えば先頭から50番目のレコードを読み込みたい場合でも、先頭から順番にレコードを49個読み込んでからようやく50番目のレコードを読み込みます。磁気テープ(例:カセットテープ)や紙テープのように、前から順番に読み込まなければならないタイプの補助記憶装置などでこの形式が用いられていますが、レコードが後ろに格納されていればいるほどアクセスの効率が悪くなるという欠点があります。
·
直接処理
乱処理とも呼ばれる方式で、アクセスしたいレコードの位置に関わらず、直接そのレコードをアクセスする方式です。順処理方式と比べてアクセスの効率が良い処理方法で、フロッピーディスクや光ディスク(CD−ROM)のように、ランダムアクセス(ディスクの好きな場所にいきなりアクセスすること)が可能な装置で良く使われます。
5. ファイル編成
ファイルをディスクに格納する際に、ファイルを構成するレコードをどのような順序で格納するかを示したものがファイル編成です。ファイル編成には様々な種類があり、ファイルの利用目的や、ディスクの性質によって効率の良いファイル編成が選ばれます。
·
順次編成ファイル(SAM:Sequential Access Method)
ファイルのデータを頭から順番にレコード単位で記録する方式で、最も単純な編成方法です。順次編成ファイル方式の利点、欠点は以下の通りです。
利点:
·
データを頭から連続して記録しているために、他の方式に比べて無駄がない。
·
他の方式と比べて大量のデータを効率よく処理することが可能である。
·
磁気テープをはじめとし、任意の種類の記憶媒体で使用可能である。
欠点:
·
ファイルの処理方式は順処理のみである。
·
ファイルのデータを更新した場合の処理が大変(新しくファイルを作るetc.)である。
例えば順次編成ファイルで以下の図のような形でファイルが保存されている場合、ファイルBの内容を更新した結果、ファイルのサイズが増えた場合はファイルBを元の場所で増やすわけには行かないため、ファイルBを別の場所へ移動させる必要があります。また、移動した結果、もともとファイルBがあった領域が開き領域になってしまいます。
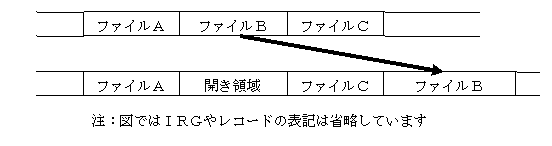
また、ファイルを変更した結果ファイルのサイズが小さくなった場合は、上記のように別の場所にファイルを移動させるか、以下のように同じ場所でファイルのサイズを縮小するか方法が考えられますが、いずれの場合もファイルBをほとんどまるごと書きなおす必要があり、またディスクに無駄な開き領域ができてしまいます。

·
直接編成ファイル(DAM:Direct Access Method)
直接編成ファイルは、ファイルを構成するそれぞれのレコードのキーに番号を設定し、そのキー番号からアクセスするレコードの位置を計算する方法です。
例えば、ファイルに学生の成績一覧を格納し、一つのレコードに一人分の学生のデータを格納する場合、学生章番号をレコードのキーとすることができます。例えば以下のような学生のデータを直接編成ファイル方式でファイルに保存する例を挙げます。
|
学生証番号 |
名前 |
|
1 |
田中 |
|
2 |
佐藤 |
|
3 |
鈴木 |
|
7 |
小泉 |
|
9 |
竹中 |
![]() この例の場合、それぞれの学生のデータは以下のように自分の学生章番号に対応するレコードに格納されます。(四角の左の数字がレコード番号。データの左の数字がキー)
この例の場合、それぞれの学生のデータは以下のように自分の学生章番号に対応するレコードに格納されます。(四角の左の数字がレコード番号。データの左の数字がキー)
|
0 |
|
|
5 |
|
|
1 |
1 田中の成績データ |
|
6 |
|
|
2 |
2 佐藤の成績データ |
|
7 |
7 小泉の成績データ |
|
3 |
3 鈴木の成績データ |
|
8 |
|
|
4 |
|
|
9 |
9 竹中の成績データ |
利点:
·
ファイルの処理方式は順処理、直接処理共に可能である。
·
直接処理が使用可能なのでどのレコードもアクセス時間がほぼ一定になる。
·
レコードの更新や削除の際の手間が少ない。例えば学生証番号が5番の小渕さんのデータを追加する場合は、5番のレコードにデータを格納すれば良いので順次編成ファイルの場合のように新しいファイルを作成する必要がない。また、佐藤さんのデータをファイルから削除するには、2番のレコードの内容を削除すれば良い。
欠点:
·
磁気テープのような記憶媒体ではこの方式は使えない。
·
上記の例のように、キーが飛び飛びの値を取る場合、多くのレコードが未使用のままになるため、記憶効率が低い。
先ほどの例では、キーを直接レコード番号に対応させていましたが、この方法のことを直接アドレス方式と呼びます。直接アドレス方式では、例えば銀行の顧客データのようにキーの番号が7桁(0000001〜9999999)のように非常に大きな数になる場合はレコードをその数だけ用意しなければなりません。また、そのような場合に実際に使用されるキーの番号の割合が(例えば10%のように)少ない場合、ファイルの中で無駄なレコードが非常に多くなります。そこで、キーの番号に対して特定の計算を行い、その計算結果をレコードのアドレスに変換するという間接アドレス方式が考案されました。
間接アドレス方式で使われる計算方法には、除算法、基数変換法、重ね合わせ法などがありますが、授業では除算法の例を説明します。除算法ではキーを特定の数字で割った余りをレコード番号として使用します。わかりやすいようにファイルが0〜19の20個のレコードで構成されている状態で、以下の生徒のデータを除算法で格納してみましょう。
レコードの数が20なので、それぞれの学生の学生章番号を20で割り余りを求めます(下の表では余りの列に計算結果を表示しています)
|
学生証番号 |
名前 |
余り |
|
学生証番号 |
名前 |
余り |
|
1 |
田中 |
1 |
|
210 |
伊藤 |
10 |
|
14 |
佐藤 |
14 |
|
226 |
板垣 |
6 |
|
25 |
鈴木 |
5 |
|
304 |
土井 |
4 |
|
37 |
小泉 |
17 |
|
500 |
橋本 |
0 |
|
125 |
竹中 |
5 |
|
624 |
杉田 |
4 |
余りが計算できたら、余りをキーとして対応する生徒のデータをキーのレコード番号に順番に格納します。この時格納しようとしたレコードに既に他の生徒のデータが格納されていた場合はあいているレコードが見つかるまで次のレコードを探し、見つかったレコードにデータを格納します。この例の場合、竹中さんのデータを格納しようとした場合、5番目のレコードには既に鈴木さんのデータが格納されているので、次のあいている6番目のレコードに竹中さんのデータを格納します。このように、すでに対応するキーのレコードに既にデータが格納されていたことをシノニムが発生したと言います。
下に除算法を使って上記のデータをレコードに格納した結果を表示しています。この中でレコード6,7,8に格納されている3人のデータにシノニムが発生しています。
|
0 |
500 橋本 |
5 |
25 鈴木 |
10 |
210 伊藤 |
15 |
|
|
1 |
1 田中 |
6 |
125 竹中 |
11 |
|
16 |
|
|
2 |
|
7 |
226 板垣 |
12 |
|
17 |
37 小泉 |
|
3 |
|
8 |
625 杉田 |
13 |
|
18 |
|
|
4 |
304 土井 |
9 |
|
14 |
14 佐藤 |
19 |
|
間接アドレス方式は、キーの番号が飛び飛びになっている場合でも、レコードの数を必要な数(データの数)だけ用意すれば良いので無駄がなく、直接アドレス方式に比べて効率よくデータを格納できます。しかし、その反面うまく計算方法を設定しないとシノニムが大量に発生し、データの検索の効率が落ちてしまうという欠点があります。
·
索引付き順次編成ファイル
索引付き順次編成ファイルは順次編成ファイル方式に索引をつけることで直接処理を可能にするという方式です。別の言葉で言うと、レコードを探す際に「まず索引をひいて大雑把な位置を調べ、その位置から順番にレコードを検索する」というものです。

索引にすべてのキーに対応するレコードの位置を格納するのはキーの数が多くなった場合に効率が悪いので、索引は飛び飛びのレコードに対して行います。索引には、そのキーより小さな番号のキーを探すには何番目のレコードから探せばよいかが格納されています。例えば以下の図の場合、キー番号が14のレコードのデータを検索するにはまず索引をみて、14以上で一番小さな番号を探します。19がそれに該当するので19の横に記述されている3番目のレコードから順番にレコードを検索します。目的のキーが14のレコードは3,4,5と3回レコードを調べることでたどり着くことができるので結果として3回レコードをアクセスすれば目的のデータを見つけることができます。
この方法では、ファイルに新しくレコードを追加する場合に備えてあふれ領域というレコードが用意されています。例えば100〜199番のレコードがあふれ領域として用意されていた場合で、上記のファイルに新しくキー番号が15番の竹内さんのデータを挿入する場合、100番のレコードに竹内さんのデータを格納し、索引の部分を以下のように変更します(灰色の部分が変更された部分)。
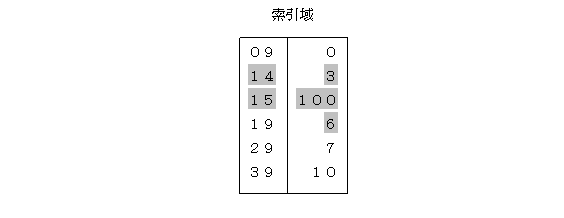
このように、索引付き順次編成ファイル方式は、ファイルの内容を更新した場合でも、順次編成ファイル方式のように新しくファイルを作成する必要はありませんが、更新を行うと「キーの順番にレコードが保存されている」という性質が壊れてしまうために索引やファイル内のレコードの構造がいびつになり、検索の効率が悪くなってしまいます。これを解消するために一定以上の更新を行うとファイルをと索引を作り直してキーの順番にレコードが保存されるように再構成を行うのが一般的です。
·
区分編成ファイル(PAM:Partitional Access Method)
索引付き順次編成ファイルの発展形で、一つのファイルを複数の順次編成ファイル方式で記述された部分(これをメンバと呼びます)に分割し、それぞれのメンバがどのレコードから格納されているかを記した索引を作成する方式です。この方法は、順次編成ファイルと索引順次編成ファイルの両方の特徴をもっています。
·
仮想記憶編成ファイル(VSAM:Virtual Storage Access Method)
順次、直接、索引順次、区分編成法の考え方を一つにまとめたファイル編成法で、平たく言えばそれぞれの性質のいいとこ取りをした方式である。この方法の仕組みはかなり複雑なので授業では説明しませんが、現在の多くのOSで仮想記憶編成ファイル方式が採用されています。
·
ファイルの処理方式の使い分け
こうしてみるとVSAMが最もすぐれているのですべてVSAMでやればいいのではないかと思うかもしれませんが、VSAMは高度な計算能力を必要とするので小規模なシステムでは仕組みが簡単で機械の性能が低くても実現できるVSAM以外の方式のファイルシステムが現在でも使用されています。例えば、一旦書き込んでしまった後は二度と変更をすることがないとわかっているようなファイルを格納する場合は、順次編成ファイル方式の多くの欠点が解消され、単純で大量のデータを効率よく格納できるという利点を活かすことができるようになります。このように使用するシステムの要求にあった処理方式が何かを見極め、状況に応じて方式を使い分けることが重要です。
6. 応用ソフトウェア
基本ソフトウェアは、コンピュータの基本的な動作を司るOSや、コンピュータのプログラムを作成するための言語処理ソフトウェアのように、コンピュータの中で欠かすことのできない基本的な処理をおこなうソフトウェアです。これに対し、それぞれの特別な目的のために作られたソフトウェアのことを応用ソフトウェアと呼びます。応用ソフトウェアは、目的の数だけつくることができるのですべてをここで紹介することは不可能です。ここでは、代表的な応用ソフトウェアについて紹介します。
·
ワードプロセッサ
一般にワープロと略してよばれるソフトウェアで、見栄えを重視した文章を作成する際に使われます。Word、一太郎などが代表的なワープロです。
·
表計算
家計簿や成績表など、数多くのデータの計算を扱う為のソフトウェアで、計算能力を持った表を作ることができます。Excelが代表的な表計算ソフトウェアです。
·
ウェブブラウザ
WWWを閲覧するためのソフトウェアです。Internet
ExplorerやNetscapeなどがあります。
·
メールソフト
電子メールの送受信を行う為のソフトウェアです。ウェブブラウザとメールソフトは現在一般のユーザが最もよく使うソフトウェアと言えるでしょう。
·
データベース
企業の顧客情報等、大量の情報を扱う(格納・検索など)為のソフトウェアで、現在のコンピュータソフトウェアの中でも非常に重要なソフトウェアの一つです。データベースを使った身近な例としては、YahooやGoogleなどのサーチエンジンや、インターネット上で見ることができる辞書や地図や時刻表などが挙げられます。先ほど説明した、ファイルシステムもファイルという情報を扱う(格納・検索が可能な)データベースの一種と考えることができます。データベースに関しては、次回から授業で詳しく解説する予定です。
·
その他
この他にも画像処理ソフトやゲームなどさまざまな応用ソフトウェアが存在します。
7. 課題
以下のデータを直接編成ファイル方式でプリントの8Pと同じ方法でファイルに格納した場合、0から19番目のそれぞれのレコードには誰のデータが格納されるかを計算せよ。
答えは「データの格納されているレコード番号」、「学生証番号」、「名前」の組で1行に一つのレコードを記述すること。
記述例:
1,6,田中
2,12,佐藤
・・・
|
学生証番号 |
名前 |
|
学生証番号 |
名前 |
|
6 |
田中 |
|
114 |
伊藤 |
|
12 |
佐藤 |
|
147 |
板垣 |
|
34 |
鈴木 |
|
193 |
土井 |
|
76 |
小泉 |
|
352 |
橋本 |
|
106 |
竹中 |
|
647 |
杉田 |
また、上記のデータを索引付き順次編成ファイル形式で保存し、3つのレコードおきに索引をつけた場合索引域はどのようになるかを記述せよ。答えは「キー」、「レコード番号」の組で1行に一つの索引を記述すること。
出席、課題のメールはta04k026@edu.i.hosei.ac.jpにお願いします。
質問のメールなどは、sigesada@edu.i.hosei.ac.jpまでお願いします。
授業の資料の最新版はhttp://www.edu.i.hosei.ac.jp/~sigesada/にあります。